Sub-JEPA: a simple fix to LeCun group's LeWorldModel that consistently improves performance [P]
Mirrored from r/MachineLearning for archival readability. Support the source by reading on the original site.
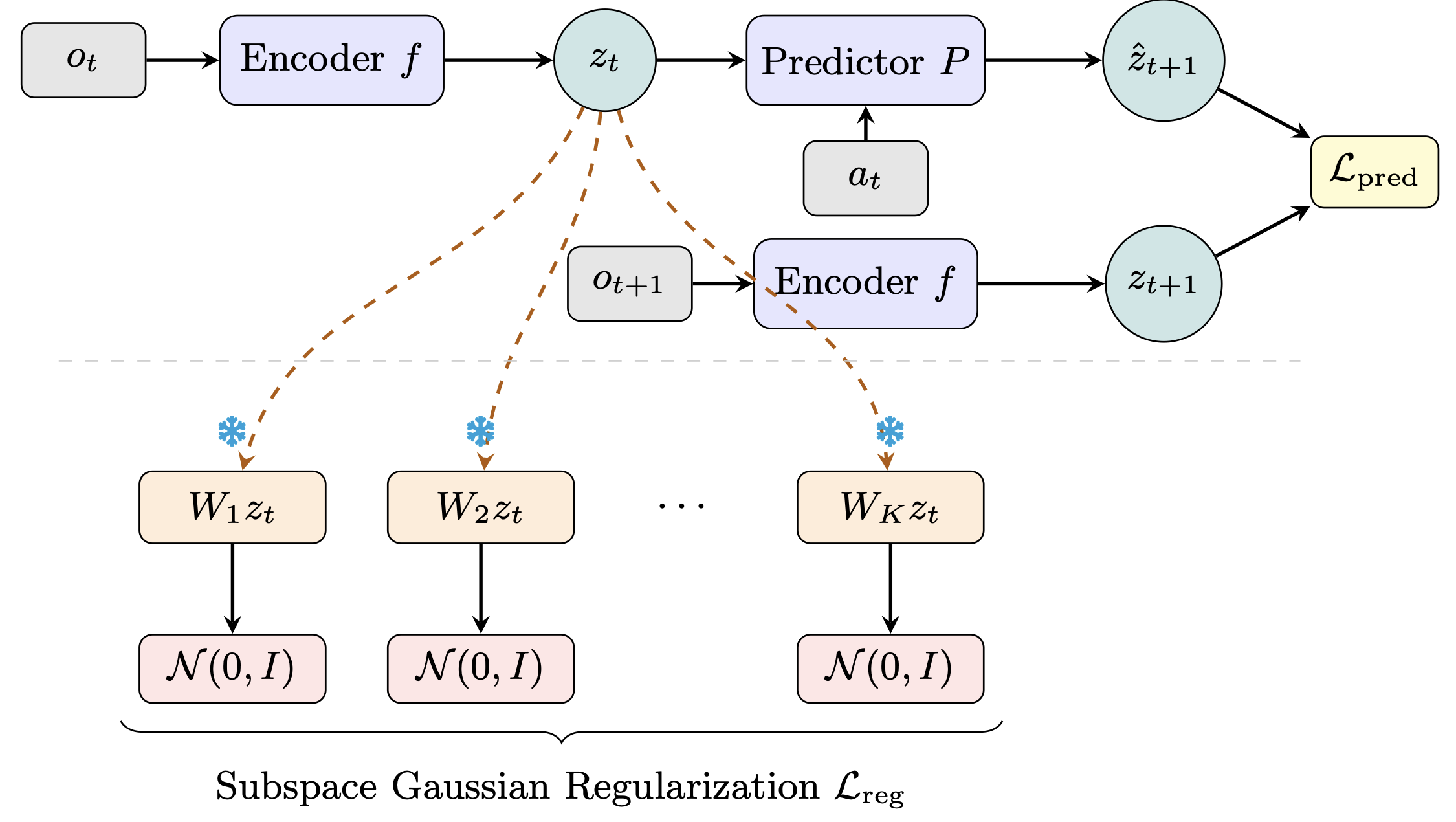
World models learn compact latent representations for planning without pixel reconstruction. LeWorldModel (LeWM), from LeCun's group at NYU, achieves stable end-to-end JEPA training by enforcing an isotropic Gaussian prior over the full latent space.
The flaw: real environment dynamics live on low-dimensional manifolds, so a global high-dimensional Gaussian is an overly rigid prior — mismatched to the task geometry. LeWM itself struggles most on low-intrinsic-dimension tasks like Two-Room.
Our fix (Sub-JEPA): apply the Gaussian regularization inside multiple frozen random orthogonal subspaces instead. This relaxes the global constraint while keeping the anti-collapse benefit. No new hyperparameters, same two-term objective.
Sub-JEPA consistently outperforms LeWM across all four benchmarks, with up to +10.7 pp on Two-Room. We also observe straighter latent trajectories and better physical state decodability as emergent benefits.

🌐 Project: https://kaizhao.net/sub-jepa
💻 Code: https://github.com/intcomp/sub-jepa
📄 Paper: https://arxiv.org/pdf/2605.09241
[link] [comments]
More from r/MachineLearning
-
Improving machine-translated novels via style transfer — looking for advice on the faithfulness/fluency tradeoff [P]
Jul 2
-
How papers are selected for Best Paper, Oral, or Highlight presentation at major ML/CV conferences such as CVPR, ICCV, ECCV, NeurIPS, and ICLR? [D]
Jul 2
-
BMVC 2026 Review Discussion Thread [D]
Jul 2
-
Has anyone tried this approach with Fast Byte Latent Transformers ? [R]
Jul 2
Discussion (0)
Sign in to join the discussion. Free account, 30 seconds — email code or GitHub.
Sign in →No comments yet. Sign in and be the first to say something.