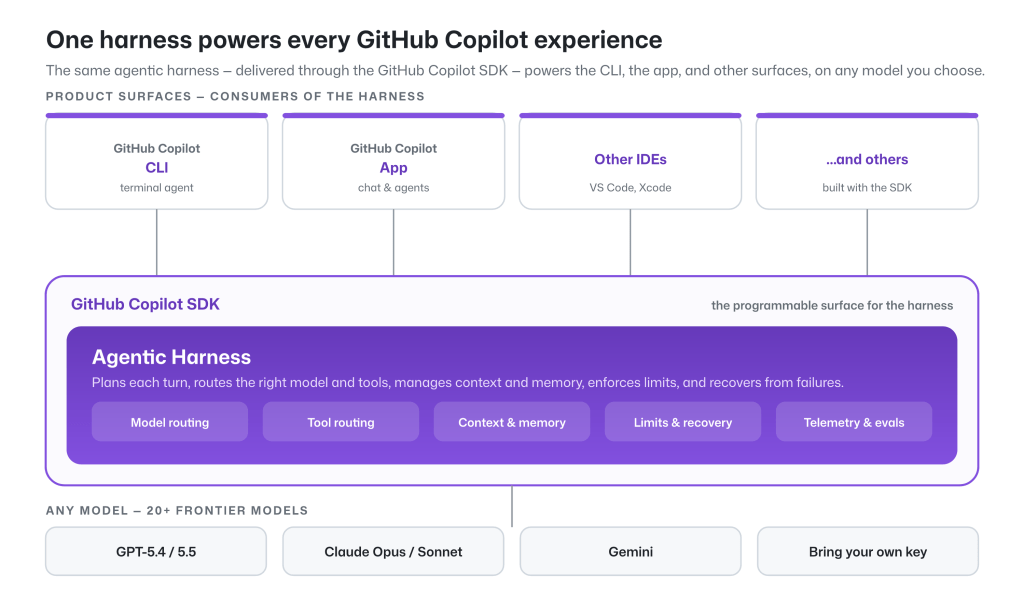
News / #benchmark Tag Benchmark 500 articles archived under #benchmark · RSS Sign in to follow r/MachineLearning community 4d ago Benchmarking Self-Hosted Gemma 2 9B vs. Frontier APIs: The FP8 Quantization Prefill Tax and VRAM Realities on an NVIDIA L4 [P] When evaluating migrating production LLM workloads off commercial cloud APIs, the conversation usually gets oversimplified into a trade-off between quality and infrastructure cost. To look past clean, isolated averages, I built a repeatable evaluation matrix using a real-world… 29 r/LocalLLaMA community 4d ago Running GLM5.2 on budget hardware < $2500. Too many times I hear people whine about not being ble to run SOTA models or claim it would require $50k, or $100k. https://www.ebay.com/itm/398079051468 Epcy Motherboard & CPU - $460 https://www.ebay.com/itm/206374955959 P40 24gb - $230 get 2 - $460… 19 r/MachineLearning community 5d ago I silently break training codes or configs so I made pybench [P] It is like pytest but for statistical tests: it ensures no regression of your metrics at a statistical level. It manages tedious things such that seeds, past benchmark results, ... Simple CLI working like pytest but with benchmarks/ directory instead of tests/: pybench # 1st… 38 r/LocalLLaMA community 5d ago "What should I do?" - consider post-training This is in response to the common post where OP has acquired some cool hardware and is wondering what to do with it. The standard response is always (1) download model X, (2) benchmark it on tps, (3) share screenshots. I argue this is boring and intellectually lazy, and propose… 18 r/LocalLLaMA community 5d ago What's one local AI workflow you wish you'd discovered sooner? There are a lot of posts about the models and benchmarks, but I am more interested in the workflows that people use. What is one workflow that really saved you time or made your local LLM more useful? It could be anything—RAG, MCP, coding agents, organizing prompt, document… 23 Hugging Face Daily Papers research 5d ago Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments Abstract A web-based benchmark evaluates agent generalization across challenging scenarios, revealing significant gaps between current agentic systems and human performance in temporal perception, graphical understanding, and 3D reasoning. Generated by… 10 Hugging Face Daily Papers research 6d ago CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies Abstract CoffeeBench evaluates LLM agents in a multi-agent economic simulation where firms interact over 90 days to maximize profits, revealing differences in communication patterns and performance among various models. Generated by Qwen/Qwen2.5-Coder-32B-Instruct As LLM agents… 4 Hugging Face Daily Papers research 6d ago JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting Abstract JetSpec is a speculative decoding framework that combines efficient forward drafting with causal conditioning to improve LLM inference speed and acceptance rates across various benchmarks. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Speculative decoding (SD)… 17 arXiv — Machine Learning research 6d ago The Red Queen G\"odel Machine: Co-Evolving Agents and Their Evaluators arXiv:2606.26294v1 Announce Type: new Abstract: Self-improving agents are state-of-the-art (SOTA) on agentic coding benchmarks and have recently been extended to general domains. However, their search methods generally assume a stationary evaluation criterion: a fixed verifier,… 25 arXiv — Machine Learning research 6d ago Otter Weather: Skillful and Computationally Efficient Medium-Range Weather Forecasting arXiv:2606.26421v1 Announce Type: new Abstract: State-of-the-art medium-range AI weather models can outperform traditional Numerical Weather Prediction (NWP) but require massive training budgets. This restricts usage for under-resourced groups and severely limits fast model… 4 arXiv — NLP / Computation & Language research 6d ago DualEval: Joint Model-Item Calibration for Unified LLM Evaluation arXiv:2606.26429v1 Announce Type: cross Abstract: Current LLM evaluation relies on two complementary but often disconnected signals: static benchmarks with objective correctness labels and arena-style preference data that better reflect open-ended user interactions. We introduce… 24 arXiv — Machine Learning research 6d ago Can Large Language Models Reliably Code Qualitative Humanitarian Data? A Benchmark Study Against Human Expert Adjudication arXiv:2606.26541v1 Announce Type: new Abstract: Data from affected populations are crucial for informing humanitarian response, but their value depends on timely and consistent interpretation of nuanced accounts of need. Humanitarian organizations often lack the staff, time, and… 4 arXiv — Machine Learning research 6d ago RSPC: A Benchmark for Modeling Stress and Psychiatric Conditions in Digitally Mediated Relationships using Psychiatrist Annotations arXiv:2606.27247v1 Announce Type: new Abstract: In NLP, mental health conditions are often modeled as isolated phenomena, without interpersonal context. We use Reddit posts about long-distance relationships to capture both mental health distress and associated relational… 24 arXiv — NLP / Computation & Language research 6d ago Know2Guess: A Contamination-Aware Multi-Zone Benchmark for Knowledge-Boundary Evaluation in Large Language Models arXiv:2606.26101v1 Announce Type: new Abstract: Reliable evaluation of large language models should separate supported answering from unsupported guessing without conflating either with data contamination, prompt idiosyncrasy, or generic refusal behavior. We present a… 21 arXiv — NLP / Computation & Language research 6d ago Where Larger Models Excel: The Primacy of Constraint-Guided Reasoning arXiv:2606.26108v1 Announce Type: new Abstract: Larger language models consistently outperform smaller ones on reasoning benchmarks, yet the reasoning differences underlying this gap remain underexplored. Across benchmarks in mathematics, physics, chemistry, and programming, we… 35 arXiv — NLP / Computation & Language research 6d ago CAT-Q: Cost-efficient and Accurate Ternary Quantization for LLMs arXiv:2606.26650v1 Announce Type: new Abstract: In this paper, we present CAT-Q, Cost-efficient and Accurate Ternary Quantization, for compressing and accelerating LLMs. Unlike existing state-of-the-art ternary quantization methods that rely on data-intensive and costly… 9 arXiv — NLP / Computation & Language research 6d ago SocialPersona: Benchmarking Personalized Profiling and Response with Multimodal Social-Media Context arXiv:2606.26654v1 Announce Type: new Abstract: Personalized language-model assistants are often evaluated through a memory lens: can a model recall preferences users have explicitly stated in dialogue? More comprehensive personalization demands a harder capability -- inferring… 13 arXiv — NLP / Computation & Language research 6d ago NuclearQAv2: A Structured Benchmark for Evaluating Domain-Science Competence in Large Language Models arXiv:2606.27047v1 Announce Type: new Abstract: Large language models (LLMs) have demonstrated strong performance across a wide range of tasks, but ensuring their reliability in highly technical domains remains a significant challenge. In nuclear engineering, problem solving… 16 arXiv — NLP / Computation & Language research 6d ago HarmVideoBench: Benchmarking Harmful Video Understanding in Large Multimodal Models arXiv:2606.27187v1 Announce Type: cross Abstract: Large vision-language models (LVLMs) have recently shown immense potential in automated content moderation, sparking growing interest in developing harmful-video benchmarks. However, we identify two primary limitations in… 25 Hugging Face Daily Papers research 6d ago OpenBioRQ: Unsolved Biomedical Research Questions for Agents Abstract A new biomedical benchmark evaluates agentic models' ability to verify sources and avoid false citations by testing unsolved research questions with no answer keys, revealing significant failures in retrieval-grounded reasoning and tool usage. Generated by… 9 r/LocalLLaMA community 6d ago Stop waiting for Qwen3.7 Openweights. Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes, including 9B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks. Hugging Face:… 36 GitHub Blog — AI & ML official-blog 6d ago Evaluating performance and efficiency of the GitHub Copilot agentic harness across models and tasks Explore how the GitHub Copilot agentic harness delivers strong results across multiple benchmarks and leading token efficiency, while maintaining flexibility to choose among more than 20 models. The post Evaluating performance and efficiency of the GitHub Copilot agentic harness… 19 Hugging Face Daily Papers research 6d ago Lite Any Stereo V2: Faster and Stronger Efficient Zero-Shot Stereo Matching Abstract Lite Any Stereo V2 (LAS2) presents an efficient stereo matching approach that achieves state-of-the-art accuracy with significantly reduced latency through optimized architecture and training strategies. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Recent advances in… 9 r/LocalLLaMA community 6d ago Ornith-1.0 released on Hugging Face Including 9B Dense, 31B Dense, 35B MoE, and 397B MoE and reporting sota on different benchmark (let's see if this holds). https://huggingface.co/collections/deepreinforce-ai/ornith-10   submitted by   /u/paf1138 [link]   [comments] 26 r/MachineLearning community 6d ago CALHippo - Mapping neurons and glial cells in the human brain hippocampus in 3D using SOTA segmentation and density estimation models [R] Hello everyone! I'm posting our research work as you might be interested in how we used ML to map part of the brain cells of the human hippocampus :) We used various human brain slices at high resolution (1 micrometer per pixel) and developed a custom segmentation pipeline that… 32 r/MachineLearning community 7d ago I stopped trusting model benchmarks and started running my own eval set, here is what changed[D] Three things broke my faith in published benchmarks recently. One, Kimi K2.7 Code shipped with plus 21.8 percent on Kimi Code Bench v2, plus 11 percent on Program Bench, plus 31.5 percent on MLS Bench Lite. All three are Moonshot's own benchmarks. None were submitted to DeepSWE,… 23 Hugging Face Daily Papers research 7d ago Causal-rCM: A Unified Teacher-Forcing and Self-Forcing Open Recipe for Autoregressive Diffusion Distillation in Streaming Video Generation and Interactive World Models Abstract Autoregressive video diffusion extends diffusion distillation frameworks to real-time streaming generation through causal training paradigms, achieving state-of-the-art performance with fast convergence and interactive world modeling capabilities. Generated by… 4 Hugging Face Daily Papers research 7d ago Improved Large Language Diffusion Models Abstract Masked diffusion language models with fully bidirectional attention outperform autoregressive counterparts on various benchmarks while maintaining competitiveness with established models. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Modern large language models are… 18 Hugging Face Daily Papers research 7d ago ShutterMuse: Capture-Time Photography Guidance with MLLMs Abstract Researchers developed a new benchmark and dataset for photography assistance, along with a unified multimodal model that provides both composition guidance and pose recommendations during image capture. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Real-world photography… 12 Smol AI News news-outlet 7d ago not much happened today **Z.ai's GLM-5.2** leads in coding and agent benchmarks with top scores like **1595** on Code Arena: Frontend and **34.29%** reasoning accuracy with zero failures. Databricks improved GLM-5.2 speed to **392 tok/s** using hardware and optimizations. **Ornith-1.0**, a new… 13 arXiv — Machine Learning research 7d ago MacroLens: A Multi-Task Benchmark for Contextual Financial Reasoning under Macroeconomic Scenarios arXiv:2606.24950v1 Announce Type: new Abstract: Financial decision-making is contextual: forecasting prices, valuing companies, and assessing event exposure weigh price history, accounting fundamentals, macroeconomic regime, and contemporaneous text. A benchmark over these four… 25 arXiv — Machine Learning research 7d ago Are Tabular Foundation Models Robust to Realistic Query Distribution Shifts in Microbiome Data? arXiv:2606.24995v1 Announce Type: new Abstract: Tabular foundation models (TFMs) achieve strong performance on microbiome abundance data, yet their robustness under realistic distribution shift remains poorly characterized. We introduce a benchmark that evaluates the robustness… 22 arXiv — Machine Learning research 7d ago From Forecasting Leaderboards to Deployment Decisions: A Fail-Closed Certification Protocol arXiv:2606.24996v1 Announce Type: new Abstract: Forecasting leaderboards rank models by predictive quality, but their winners are often read as deployment-ready top-1 advice. That reading can fail when forecasts are passed through a fixed decision interface, such as an alert… 23 arXiv — NLP / Computation & Language research 7d ago Do Thinking Tokens Help with Safety? arXiv:2606.25013v1 Announce Type: cross Abstract: Today's reasoning models use thinking tokens to attain stronger performance on benchmarks than their instruction-tuned counterparts. It is also generally believed that this more "deliberative" mode should improve alignment and… 37 arXiv — Machine Learning research 7d ago FDN: Interpretable Spatiotemporal Forecasting with Future Decomposition Networks arXiv:2606.25201v1 Announce Type: new Abstract: Spatiotemporal systems comprise a collection of spatially distributed yet interdependent entities each generating unique dynamic signals. Highly sophisticated methods have been proposed in recent years delivering state-of-the-art… 21 arXiv — Machine Learning research 7d ago TopoCast: A Topological Fidelity Framework for Evaluating Transformer-Based Time Series Forecasting arXiv:2606.25439v1 Announce Type: new Abstract: Deep learning-based models have achieved state-of-the-art performance in Time Series Forecasting (TSF), yet their evaluation remains dominated by pointwise error metrics such as Mean Squared Error (MSE), which quantify numerical… 37 arXiv — NLP / Computation & Language research 7d ago LLM Performance on a Real, Double-Marked GCSE Benchmark arXiv:2606.24973v1 Announce Type: new Abstract: We introduce a dataset of 32,534 double-marked real student responses to GCSE mock exams (GCSEs are the UK's national exams, taken at age ~16), spanning 328 questions across five subjects and including handwritten work. We test… 26 arXiv — NLP / Computation & Language research 7d ago LLM-Based Scientific Peer Review: Methods, Benchmarks, and Reliability Challenges arXiv:2606.25057v1 Announce Type: new Abstract: The rapid growth of scientific submissions has pushed traditional peer review toward its scalability limits, motivating the exploration of large language models (LLMs) as intelligent automated evaluation assistants. Although recent… 11 arXiv — NLP / Computation & Language research 7d ago Riazi-8B: An Urdu Large Language Model for Mathematical Reasoning arXiv:2606.25568v1 Announce Type: new Abstract: Recent LLMs demonstrate strong mathematical reasoning capabilities, but existing gains rely heavily on English-centric training resources and benchmarks. As a result, reasoning performance degrades substantially in low-resource… 27 arXiv — NLP / Computation & Language research 7d ago Beyond Function Calling: Benchmarking Tool-Using Agents under Tool-Environment Unreliability arXiv:2606.25819v1 Announce Type: new Abstract: Large language models are increasingly deployed as agents that solve tasks by interacting with external tool environments. Although recent tool-use benchmarks increasingly cover complex task settings, they still largely assume… 26 arXiv — NLP / Computation & Language research 7d ago SpeechEQ: Benchmarking Emotional Intelligence Quotient in Socially Aware Voice Conversational Models arXiv:2606.25990v1 Announce Type: new Abstract: As multimodal conversational systems increasingly engage in spoken interaction, their ability to navigate paralinguistic social cues has become a critical bottleneck for natural human-AI communication. However, existing evaluations… 29 arXiv — NLP / Computation & Language research 7d ago Same Evidence, Different Answer: Auditing Order Sensitivity in Multimodal Large Language Models arXiv:2606.26079v1 Announce Type: new Abstract: Standard benchmarks for multimodal large language models (MLLMs) score each item on one canonical ordering and miss whether order-irrelevant shuffling changes the answer, a baseline reliability property called for by emerging AI… 31 arXiv — NLP / Computation & Language research 7d ago Evaluating LLMs on Real-World Software Performance Optimization arXiv:2606.25530v1 Announce Type: cross Abstract: Software performance optimization is a notoriously complex and manual task. Despite the growing use of Large Language Models (LLMs) for code refinement, we still lack benchmarks that capture how optimization actually happens in… 17 arXiv — NLP / Computation & Language research 7d ago Uncertainty Quantification for Computer-Use Agents: A Benchmark across Vision-Language Models and GUI Grounding Datasets arXiv:2606.25760v1 Announce Type: cross Abstract: Computer-use agents turn vision-language model (VLM) predictions into executable GUI clicks, so reliable uncertainty estimates are essential for rejection, calibration, miss-severity ranking, and spatial safety regions. Yet… 14 arXiv — NLP / Computation & Language research 7d ago How Robust is OCR-Reasoning? Evaluating OCR-Reasoning Robustness of Vision-Language Models under Visual Perturbations arXiv:2606.26041v1 Announce Type: cross Abstract: Vision-language models (VLMs) have achieved strong performance on OCR-based benchmarks and increasingly focused on text-rich understanding, but their robustness under controlled visual degradation remains insufficiently… 29 arXiv — NLP / Computation & Language research 7d ago How Pragmatics Shape Articulation: A Computational Case Study in STEM ASL Discourse arXiv:2510.23842v2 Announce Type: replace Abstract: Most state-of-the-art sign language models are trained on interpreter or isolated vocabulary data, which overlooks the variability that characterizes natural dialogue. However, human communication dynamically adapts to contexts… 31 Hugging Face Daily Papers research 7d ago EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies Abstract EBench is a comprehensive simulation benchmark for evaluating generalist mobile manipulation policies across diverse tasks and dimensions, revealing distinct capability profiles and generalization patterns among state-of-the-art models. Generated by… 18 Hugging Face Daily Papers research 7d ago MEMPROBE: Probing Long-Term Agent Memory via Hidden User-State Recovery Abstract Long-term memory in LLM agents should be evaluated as an auditable post-interaction artifact by reconstructing structured user state from the agent's memory, as demonstrated by MEMPROBE, a benchmark testing memory recovery against synthetic ground truth across 50… 21 r/MachineLearning community 7d ago Find the best open-source OCR models in one place at Papers with Code [P] Hi, I've created an overview of the most important OCR benchmarks, along with the top open models, and links to their paper and code: https://paperswithcode.co/tasks/ocr . This week, new OCR models were released by Baidu and Mistral. Baidu released Unlimited OCR , a 3B-parameter… 27 r/MachineLearning community 7d ago I made a superhuman Generals.io agent with self-play RL [P] Hi everyone, I trained a self-play RL agent for Generals.io that reached superhuman-level and ranked #1 on the human 1v1 leaderboard. It began as my master's thesis where the goal was to beat a prior algorithm based agent. We succeeded using behavior cloning, RL fine-tuning and… 6 Page 3 of 10 · 500 articles ← Newer Older →