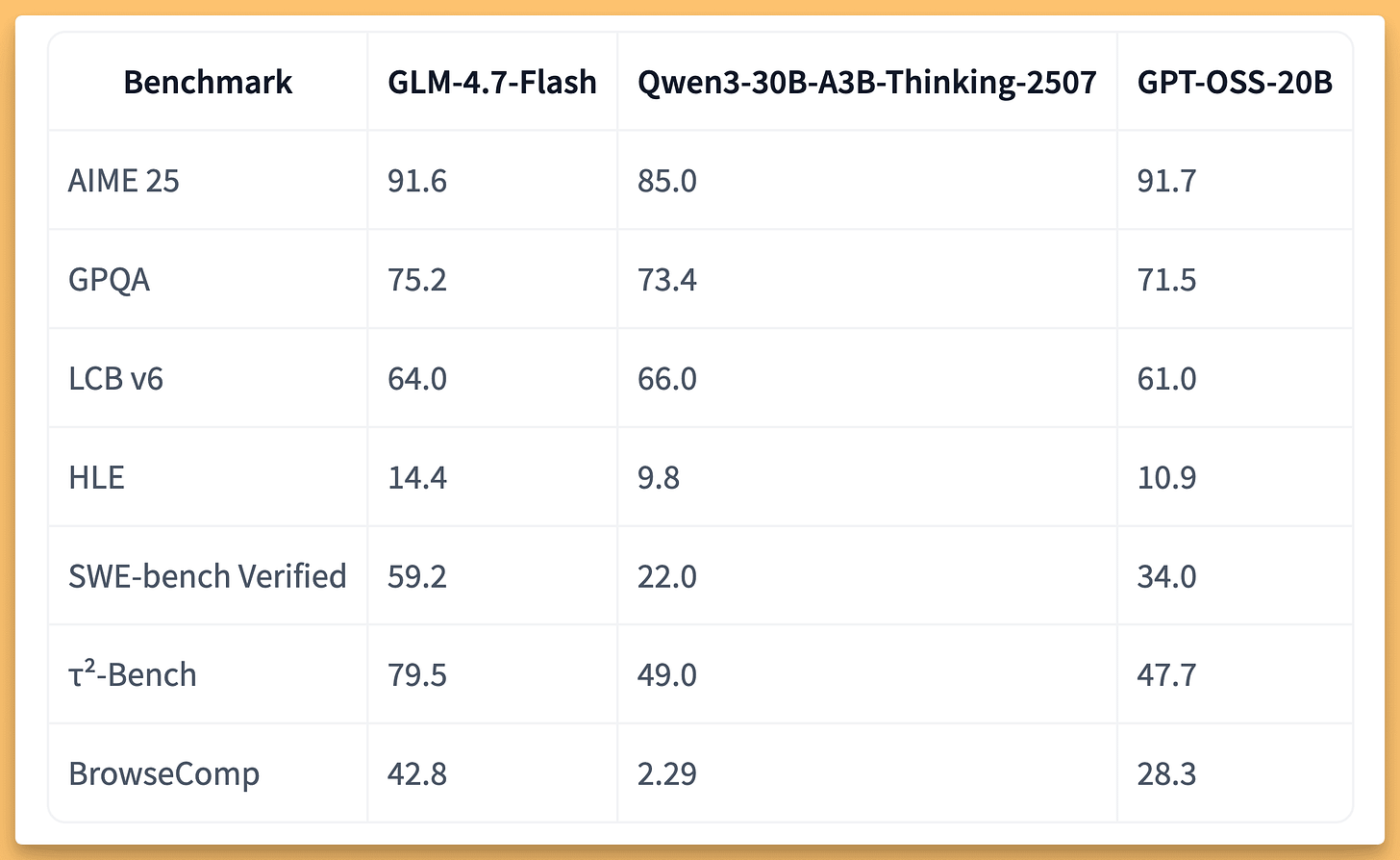
News / #voice Tag Voice 391 articles archived under #voice · RSS Sign in to follow arXiv — NLP / Computation & Language research 1mo ago Can Large Language Models Imitate Human Speech for Clinical Assessment? LLM-Driven Data Augmentation for Cognitive Score Prediction arXiv:2605.16077v1 Announce Type: new Abstract: Accurate assessment of cognitive decline from spontaneous speech remains challenging due to limited dataset size and class imbalance. In this work, we propose a large language model (LLM)-driven data augmentation framework to… 38 TechCrunch — AI news-outlet 1mo ago If you’re giving a commencement speech in 2026, maybe don’t mention AI It's tough to get graduating students excited about a future shaped by artificial intelligence. 20 r/LocalLLaMA community 1mo ago GitHub - richardr1126/openreader: An open-source read-along document reader server with high-quality TTS options, synchronized highlighting, and audiobook export for EPUB, PDF, DOCX, TXT, and MD. Sharing my latest release of OpenReader v3.0.0, an open-source text-to-speech document reader and audiobook exporter. It has been live for over a year now, and slowly has gained 300+ GitHub stars. What is OpenReader? A Next.js web app for reading and listening to EPUB, PDF, TXT,… 9 The Information — AI news-outlet 1mo ago OpenAI Buys AI Voice Startup Weights OpenAI bought Weights.GG, a small startup that made an AI voice-cloning tool called Replay, in January, according to a person familiar with the acquisition. A half dozen employees joined OpenAI, which bought the startup’s intellectual property but does not plan to integrate the… 36 r/LocalLLaMA community 1mo ago macOS support in Lemonade has graduated out of beta! All major Lemonade capabilities, including OmniRouter, coding, image gen, speech gen, and transcription are all available on Lemonade for macOS thanks to the hard work of u/GeramyL . If you're on macOS and just looking into Lemonade for the first time, we're a local AI solution… 18 r/LocalLLaMA community 1mo ago Built a fully offline suitcase robot around a Jetson Orin NX SUPER 16GB. Gemma 4 E4B, ~200ms cached TTFT, 30+ sensors, no WiFi/BT/cellular. He has opinions. Sparky runs entirely on the Jetson. Gemma 4 E4B at Q4_K_M via llama.cpp with q8_0 KV cache and flash attention. 12K context, native system role, sampler defaults from the model card. Cached TTFT around 200ms, sustained 14-15 tok/s. SenseVoiceSmall for STT, Piper for TTS with… 21 r/LocalLLaMA community 1mo ago GitHub - pwilkin/openmoss: OpenMOSS pure C++ pipeline based on GGML I'm uploading a full GGML-based pipeline for OpenMOSS ( https://huggingface.co/OpenMOSS-Team/MOSS-TTS ) that I've vibe-coded for myself in case someone else finds it useful. TTS models are notoriously annoying to set up due to the entire Python ecosystem, so I decided I'd make… 29 arXiv — NLP / Computation & Language research 1mo ago A Calculus-Based Framework for Determining Vocabulary Size in End-to-End ASR arXiv:2605.14427v1 Announce Type: new Abstract: In hybrid automatic speech recognition (ASR) systems, the vocabulary size is unambiguous, typically determined by the number of phones, bi-phones, or tri-phones present in the language. In contrast, end-to-end ASR systems derive… 15 arXiv — NLP / Computation & Language research 1mo ago Streaming Speech-to-Text Translation with a SpeechLLM arXiv:2605.14766v1 Announce Type: new Abstract: Normally, a system that translates speech into text consists of separate modules for speech recognition and text-to-text translation. Combining those tasks into a SpeechLLM promises to exploit paralinguistic information in the… 7 arXiv — NLP / Computation & Language research 1mo ago From Text to Voice: A Reproducible and Verifiable Framework for Evaluating Tool Calling LLM Agents arXiv:2605.15104v1 Announce Type: new Abstract: Voice agents increasingly require reliable tool use from speech, whereas prominent tool-calling benchmarks remain text-based. We study whether verified text benchmarks can be converted into controlled audio-based tool calling… 19 arXiv — NLP / Computation & Language research 1mo ago A Benchmark for Early-stage Parkinson's Disease Detection from Speech arXiv:2605.14066v1 Announce Type: cross Abstract: Early-stage Parkinson's disease (EarlyPD) detection from speech is clinically meaningful yet underexplored, and published results are hard to compare because studies differ in datasets, languages, tasks, evaluation protocols, and… 21 Hugging Face Daily Papers research 1mo ago EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents Abstract EVA-Bench presents a comprehensive evaluation framework for voice agents that simulates realistic conversations and measures performance across multiple voice-specific failure modes using novel accuracy and experience metrics. AI-generated summary Voice agents,… 21 Hacker News — AI on Front Page community 1mo ago MIT: 20% drop in incoming graduate students Article URL: https://president.mit.edu/writing-speeches/video-transcript-message-president-kornbluth-about-funding-and-talent-pipeline Comments URL: https://news.ycombinator.com/item?id=48136262 Points: 211 # Comments: 195 21 r/LocalLLaMA community 1mo ago [MIT] RLCR: Teaching AI models to say "I'm not sure" Confidence is persuasive. In AI systems, it is often misleading. Today's most capable reasoning models share a trait with the loudest voice in the room: They deliver every answer with the same unshakable certainty, whether they're right or guessing. Researchers at MIT's Computer… 23 r/LocalLLaMA community 1mo ago Got local Qwen 3.5/3.6 generating meeting summaries entirely offline on an M4 Max. Demo with Wi-Fi off. This is the future. I'm the founder behind Hedy, an AI meeting app. I'm a huge supporter of Local AI, and we've been working on making it "consumer friendly". Speech recognition in Hedy has always run on-device (whisper.cpp and now also parakeet). What just shipped is that the rest of the AI… 22 r/LocalLLaMA community 1mo ago Scenema Audio: Zero-shot expressive voice cloning and speech generation We've been building Scenema Audio as part of our video production platform at scenema.ai, and we're releasing the model weights and inference code. The core idea: emotional performance and voice identity are independent. You describe how the speech should be performed (rage,… 17 r/LocalLLaMA community 1mo ago Built an open-source one-prompt-to-cinematic-reel pipeline on a single GPU — FLUX.2 [klein] for character keyframes, Wan2.2-I2V for animation, vision critic with auto-retry, music + 9-language narration in the same pipeline Shipped this for the AMD x lablab hackathon. Attached video is one of the actual reels the pipeline produced - one English sentence in, finished mp4 with characters, story, music, and voice-over out (fast demo video, not the best quality). ~45 minutes end-to-end on a single AMD… 13 Hugging Face Daily Papers research 1mo ago Vividh-ASR: A Complexity-Tiered Benchmark and Optimization Dynamics for Robust Indic Speech Recognition Abstract Research identifies studio-bias in multilingual ASR fine-tuning and proposes R-MFT method to improve spontaneous speech performance while maintaining efficiency. AI-generated summary Fine-tuning multilingual ASR models like Whisper for low-resource languages often… 20 r/MachineLearning community 1mo ago Scenema Audio: Zero-shot expressive voice cloning and speech generation [N] We've been building Scenema Audio as part of our video production platform at scenema.ai, and we're releasing the model weights and inference code. The core idea: emotional performance and voice identity are independent. You describe how the speech should be performed (rage,… 37 r/LocalLLaMA community 1mo ago DramaBox - Most Expressive Voice model ever based on LTX 2.3 The Most Expressive Voice Model. Github: https://github.com/resemble-ai/DramaBox HF Model: https://huggingface.co/ResembleAI/Dramabox HF Space: https://huggingface.co/spaces/ResembleAI/Dramabox   submitted by   /u/manmaynakhashi [link]   [comments] 22 arXiv — NLP / Computation & Language research 1mo ago Predicting Psychological Well-Being from Spontaneous Speech using LLMs arXiv:2605.11303v1 Announce Type: new Abstract: We investigate the use of Large Language Models (LLMs) for zero-shot prediction of Ryff Psychological Well-Being (PWB) scores from spontaneous speech. Using a few minutes of voice recordings from 111 participants in the PsyVoiD… 7 arXiv — NLP / Computation & Language research 1mo ago Mechanistic Interpretability of ASR models using Sparse Autoencoders arXiv:2605.12225v1 Announce Type: new Abstract: Understanding the internal machinations of deep Transformer-based NLP models is more crucial than ever as these models see widespread use in various domains that affect the public at large, such as industry, academia, finance,… 24 arXiv — NLP / Computation & Language research 1mo ago Mind the Pause: Disfluency-Aware Objective Tuning for Multilingual Speech Correction with LLMs arXiv:2605.12242v1 Announce Type: new Abstract: Automatic Speech Recognition (ASR) transcripts often contain disfluencies, such as fillers, repetitions, and false starts, which reduce readability and hinder downstream applications like chatbots and voice assistants. If left… 5 r/LocalLLaMA community 1mo ago I built Derpy Turtle: The Kokoro Trainer, a GUI for training better Kokoro voices with RVC I’ve been working on a tool called Derpy Turtle: The Kokoro Trainer. It started as a random-walk experiment for Kokoro voices, but it has grown into its own thing: a Windows GUI for creating better local voice outputs by combining Kokoro voice search with RVC voice conversion.… 9 Latent.Space news-outlet 1mo ago [AINews] Thinking Machines' Native Interaction Models - TML-Interaction-Small 276B-A12B - advances SOTA Realtime Voice and kills standard VAD well done, Team Thinky. 26 Latent.Space news-outlet 1mo ago [AINews] GPT-Realtime-2, -Translate, and -Whisper: new SOTA realtime voice APIs OpenAI continues deploying GPT-5 everywhere 18 Smol AI News news-outlet 1mo ago GPT-Realtime-2, -Translate, and -Whisper: new SOTA realtime voice APIs **OpenAI** released **GPT-Realtime-2**, a voice model with **GPT-5-class reasoning**, tool use, interruption handling, and extended context windows up to **128K tokens**, achieving top scores on **Big Bench Audio** and **Conversational Dynamics** benchmarks. They also launched a… 22 OpenAI news 1mo ago How OpenAI delivers low-latency voice AI at scale How OpenAI rebuilt its WebRTC stack to power real-time Voice AI with low latency, global scale, and seamless conversational turn-taking. 26 vLLM releases dev-tools 2mo ago v0.19.2rc0: [Bugfix] Fix k_proj's bias for GLM-ASR (#40160) Signed-off-by: Rishapveer Singh singhrishapveer@gmail.com 4 NVIDIA Developer Blog official-blog 3mo ago Maximize AI Infrastructure Throughput by Consolidating Underutilized GPU Workloads In production Kubernetes environments, the difference between model requirements and GPU size creates inefficiencies. Lightweight automatic speech recognition... 38 NVIDIA Developer Blog official-blog 3mo ago Building NVIDIA Nemotron 3 Agents for Reasoning, Multimodal RAG, Voice, and Safety Agentic AI is an ecosystem where specialized models work together to handle planning, reasoning, retrieval, and safety guardrailing. As these systems scale,... 37 Smol AI News news-outlet 3mo ago not much happened today **Google** launched **Gemini 3.1 Flash Live**, a realtime voice and vision agent model with **2x longer conversation memory**, supporting **70 languages** and **128k context**. **Mistral AI** released **Voxtral TTS**, a low-latency, open-weight text-to-speech model supporting… 31 Hugging Face official-blog 3mo ago A New Framework for Evaluating Voice Agents (EVA) Back to Articles A New Framework for Evaluating Voice Agents (EVA) Enterprise Article Published March 24, 2026 Upvote 92 Tara Bogavelli tarabogavelli ServiceNow-AI Gabrielle Gauthier Melancon gabegma ServiceNow-AI Katrina Stankiewicz kstankiewicz ServiceNow-AI Nifemi Bamgbose… 7 OpenAI Python SDK releases dev-tools 3mo ago v2.28.0 2.28.0 (2026-03-13) Full Changelog: v2.27.0...v2.28.0 Features api: custom voices ( 50dc060 ) 12 ThursdAI news-outlet 5mo ago 📆 ThursdAI - Jan 22 - Clawdbot deep dive, GLM 4.7 Flash, Anthropic constitution + 3 new TSS models From Weights & Biases - deep dive into Clawdbot, an personal AI assistant that learns and evolves, GLM 4.7 Flash, a bunch of new TTS models and Claude's new constitution! 29 Google DeepMind official-blog 6mo ago Improved Gemini audio models for powerful voice experiences Improved Gemini audio models for powerful voice interactions Share x.com Facebook LinkedIn Mail Bibo Xu Director of Product Management Tara Sainath Distinguished Research Scientist General summary Google enhanced Gemini 2.5 Flash Native Audio for better live voice agents. Expect… 37 Hugging Face official-blog 7mo ago Open ASR Leaderboard: Trends and Insights with New Multilingual & Long-Form Tracks Back to Articles Open ASR Leaderboard: Trends and Insights with New Multilingual & Long-Form Tracks Published November 21, 2025 Update on GitHub Upvote 27 Eric Bezzam bezzam Steven Zheng Steveeeeeeen Eustache Le Bihan eustlb Vaibhav Srivastav reach-vb While everyone (and their… 30 Hugging Face official-blog 8mo ago Voice Cloning with Consent Back to Articles Voice Cloning with Consent Published October 28, 2025 Update on GitHub Upvote 40 Margaret Mitchell meg Lucie-Aimée Kaffee frimelle In this blog post, we introduce the idea of a 'voice consent gate' to support voice cloning with consent. We provide an example… 24 Nonint (James Betker) research 25mo ago GPT-4o I’m very pleased to show the world GPT-4o. I came into the project mid-last year with Alexis Conneau with the goal of scaling up speech models and building an “AudioLM”. We knew we had something special late last year, but I don’t think either of us… 22 Eugene Yan research 27mo ago Building an AI Coach to Help Tame My Monkey Mind Building an AI coach with speech-to-text, text-to-speech, an LLM, and a virtual number. 20 Chip Huyen research 33mo ago Multimodality and Large Multimodal Models (LMMs) For a long time, each ML model operated in one data mode – text (translation, language modeling), image (object detection, image classification), or audio (speech recognition). However, natural intelligence is not limited to just a single modality. Humans can read, talk, and… 10 Page 8 of 8 · 391 articles ← Newer