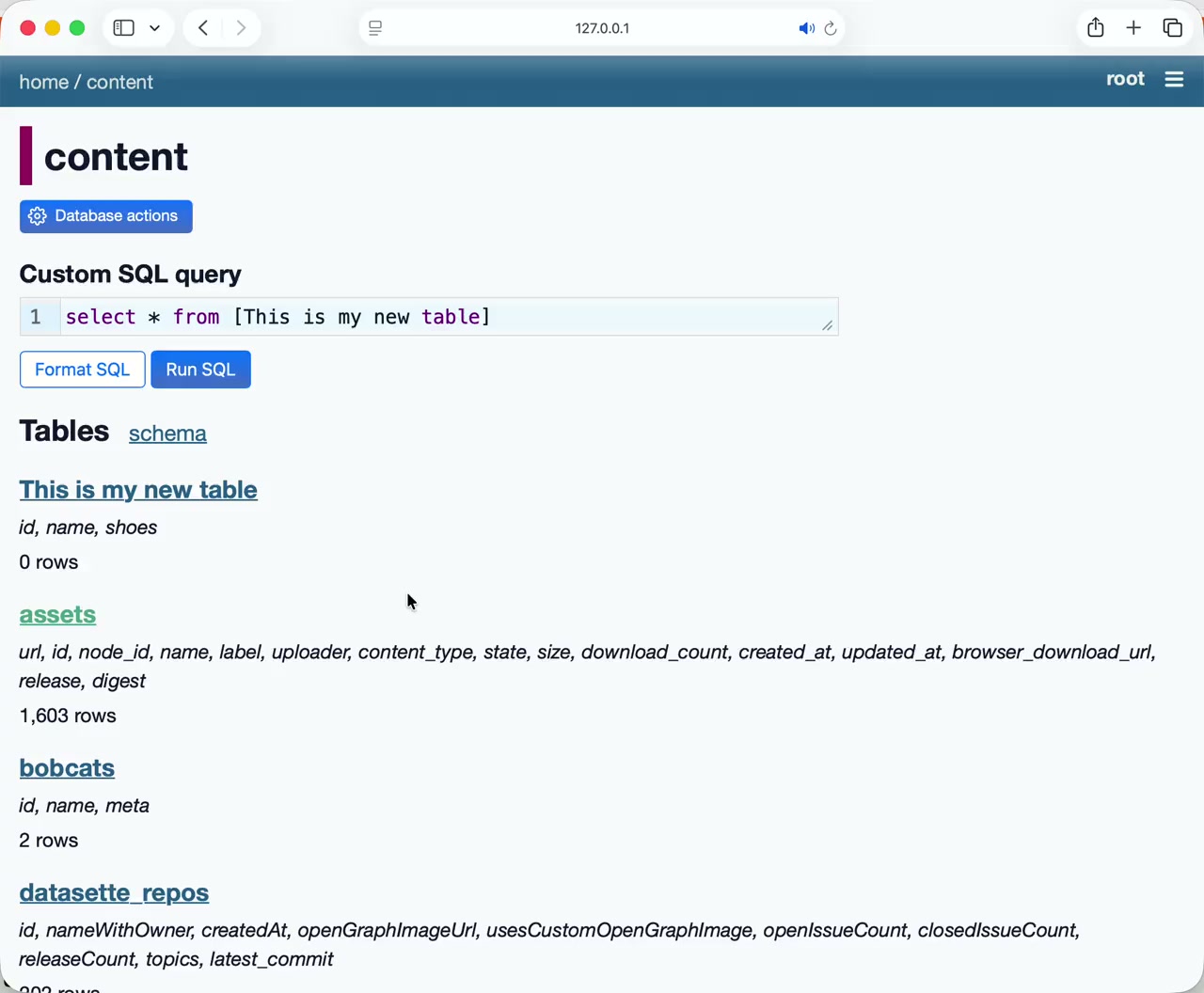
News / #model-release Tag Model releases 500 articles archived under #model-release · RSS Sign in to follow Hugging Face Daily Papers research 8d ago FedOT: Ownership Verification and Leakage Tracing via Watermarks for Federated LDMs Abstract FedOT is a novel framework that enables ownership verification and leakage tracing in federated latent diffusion models by introducing chunked watermarking and latent vector transformation to prevent watermark removal attacks. Generated by… 17 Hugging Face Daily Papers research 8d ago Holistic Data Scheduler for LLM Pre-training via Multi-Objective Reinforcement Learning Abstract A novel online data mixing framework called Holistic Data Scheduler uses reinforcement learning with a multi-objective reward function to optimize large language model pre-training efficiency and performance. Generated by Qwen/Qwen2.5-Coder-32B-Instruct The composition… 38 Hugging Face Daily Papers research 8d ago Are Text-to-Image Models Inductivist Turkeys? A Counterfactual Benchmark for Causal Reasoning Abstract Text-to-image models fail to generate counterfactual scenes because they rely on tightly coupled visual-textual patterns rather than causal reasoning, demonstrating limited understanding beyond pattern matching. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Text-to-image… 26 Hugging Face Daily Papers research 8d ago MemGUI-Agent: An End-to-End Long-Horizon Mobile GUI Agent with Proactive Context Management Abstract MemGUI-Agent addresses long-horizon mobile GUI task limitations through proactive context management using Context-as-Action (ConAct) to maintain critical information across extended sequences. Generated by Qwen/Qwen2.5-Coder-32B-Instruct MLLM-based mobile GUI agents… 32 Hugging Face Daily Papers research 8d ago MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization Abstract MobileForge enables efficient adaptation of mobile GUI agents through annotation-free learning by combining real app interaction grounding with hierarchical feedback-guided policy optimization. Generated by Qwen/Qwen2.5-Coder-32B-Instruct MLLM-based mobile GUI agents… 18 Hugging Face Daily Papers research 8d ago Tapered Language Models Abstract Tapered language models allocate more parameters to earlier layers and fewer to later layers, improving performance without increasing total parameters or compute costs. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Modern language models, including transformer,… 34 Hugging Face Daily Papers research 8d ago Beyond Reward Engineering: A Data Recipe for Long-Context Reinforcement Learning Abstract Data-centric approach using curated datasets and minimal GRPO setup significantly improves long-context reasoning in large language models, outperforming prior reinforcement learning methods. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Long-context reasoning is an… 15 Hugging Face official-blog 8d ago Introducing the FFASR Leaderboard: Benchmarking ASR in the Real World Back to Articles a]:hidden"> Introducing the FFASR Leaderboard: Benchmarking ASR in the Real World Published June 24, 2026 Update on GitHub Upvote 2 Daniel Gert Nielsen daniel-treble treble-technologies Shivam Saini whojavumusic treble-technologies Alessia Milo alessia-treble… 11 Vercel — AI dev-tools 8d ago GLM 5.2 Fast via Wafer now available on AI Gateway GLM 5.2 Fast via Wafer is now available on AI Gateway . Based on our own benchmarking across small-context, large-context, and tool-call scenarios, Wafer delivers a 2x higher throughput than other providers serving GLM-5.2 on serverless, leading on decode and end-to-end speed… 7 r/LocalLLaMA community 8d ago Mimo 2.5 is _fast_ at large context (dual RTX Pro 6000) For agentic work fast high context is king, OpenCode fills the window quickly and most models that feel snappy at 8k context turn into dial-up ADSL brrr by the time you're at 150k context deep. So I've been testing lots of models and runners trying to get "local Sonnet" on 2x… 14 Simon Willison community 8d ago datasette 1.0a35 Release: datasette 1.0a35 I'll write more about this one tomorrow, but it's a big release. Three highlights from the release notes: New "Create table" interface in the database actions menu, backed by the /<database>/-/create JSON API . It can define columns, primary keys,… 17 Hugging Face Daily Papers research 8d ago TROPT: An Open Framework for Unifying and Advancing Discrete Text Optimization Abstract A unified open-source framework for discrete text-trigger optimization that standardizes the development and execution of optimization strategies across various domains and applications. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Discrete text-trigger optimization --… 18 Hugging Face Daily Papers research 9d ago Comparing Linear Probes with Mahalanobis Cosine Similarity Abstract The Mahalanobis cosine similarity provides a theoretically grounded method for comparing linear probes that correlates strongly with out-of-distribution performance metrics. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Linear probes are widely used in interpretability… 25 r/LocalLLaMA community 9d ago Tmax-27b - a Qwen3.6-27b terminal agent for small GPUs trained with DPPO (RL) Hey everyone, wanted to share some work on making the new Tmax-27B terminal agent actually runnable on consumer hardware. What is Tmax-27B? Ai2 just released Tmax, a family of terminal-agent LLMs trained with DPPO (RL) on top of Qwen3.6. The 27B model hits ~43% on Terminal Bench… 32 r/LocalLLaMA community 9d ago OpenMythos benchmarks Hey everyone! OpenMythos benchmarks are finally here sorry it took about a week to post these. The delay was mainly because SWE-bench results weren't matching up with Qwen 3.6 27B official numbers. Turns out Qwen used a different eval harness and also refined/filtered the… 12 Hugging Face Daily Papers research 9d ago ShotcreteDepth: A Bi-modal Dataset for Robust Robotic Depth Perception in Shotcrete Construction Environments Abstract A bi-modal construction domain dataset combining stereo RGB and LiDAR data under challenging environmental conditions is introduced for autonomous system perception research. Generated by Qwen/Qwen2.5-Coder-32B-Instruct We introduce ShotcreteDepth, a bi-modal dataset… 22 r/LocalLLaMA community 9d ago UPDATE: Qwen-27B-IQ4_KS and Qwen-27B-IQ_KS_KT for ik_llama.cpp, especially for NVIDIA with 16GB VRAM Continuing 16GB VRAM Optimizations: New Qwen3.6-27B GGUF Quants (Experimental Trellis/iq4_kt & MTP) Hi everyone, I'm continuing my optimization efforts for 16GB VRAM and Nvidia GPUs from this post:… 7 Hugging Face Daily Papers research 9d ago Go-with-the-Track: Video Compositing and Motion Control with Point Tracking Abstract Go-with-the-Track unifies motion control and reference image compositing in video generation by using point-track embeddings with spatial-aware encoding and video diffusion transformers. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Filmmaking demands precise motion… 32 TechCrunch — AI news-outlet 9d ago Anthropic’s Claude Tag is learning your company, one Slack message at a time Anthropic’s new Claude Tag brings an always-on AI teammate to Slack. But beyond productivity, the feature is a strategic play to capture organizational context, institutional knowledge, and enterprise workflows. 24 OpenAI official-blog 9d ago How GPT-5 helped immunologist Derya Unutmaz solve a 3-year-old mystery GPT-5 Pro helped solve a 3-year-old immunology mystery, offering insights into T cell behavior. The breakthrough could support cancer and autoimmune research. 29 Hugging Face Daily Papers research 9d ago Libretto: Giving LLM Agents a Sense of Musical Structure Abstract Libretto provides a structured framework for symbolic music generation and revision using LLM-native grammar and statistical evaluation across musical dimensions. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Generative music systems can now produce impressive audio from… 18 Hugging Face Daily Papers research 9d ago Vera: A Layered Diffusion Model for Content-Preserving Video Editing Abstract Vera is a layered diffusion framework that preserves video content during editing by generating edit layers and alpha mattes through a Mixture-of-Transformers architecture. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Video diffusion models have enabled remarkable… 10 r/LocalLLaMA community 9d ago Krea 2 released on Hugging Face + turbo: https://huggingface.co/krea/Krea-2-Turbo   submitted by   /u/paf1138 [link]   [comments] 15 r/LocalLLaMA community 9d ago I mapped the KLD of KV cache quantization for Qwen3.6-35B-A3B and Gemma4-E2B QAT TL;DR version q8/q8 is nearly free on both models q4/q4 is useable on Qwen and catastrophic on Gemma turbo4 is sometimes slightly better, sometimes slightly worse, than q4_0 turbo3 and turbo2 allow compressing the cache to unprecedented levels - but you'll pay dearly for it K is… 9 Hugging Face Daily Papers research 9d ago An Exploratory Case Study of LLM-Assisted Refactoring and Gameplay Feature Generation in an Endless Runner Game Abstract Large language models demonstrate varying effectiveness in software development tasks, successfully completing localized refactoring but showing limitations in integrating new gameplay features within existing game systems. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 24 Hugging Face Daily Papers research 9d ago AC-ODM: Actor--Critic Online Data Mixing for Sample-Efficient LLM Pretraining Abstract AC-ODM optimizes pretraining data composition for LLMs using reinforcement learning to improve convergence speed and downstream accuracy while maintaining computational efficiency. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Optimizing pretraining data composition is… 8 Hugging Face Daily Papers research 9d ago Toward Parking Spot Occupancy Recognition: A Self-Supervised Approach Abstract A self-supervised transfer learning approach for parking spot occupancy recognition that achieves high accuracy with minimal labeled data through two-stage training and deployment strategies. Generated by Qwen/Qwen2.5-Coder-32B-Instruct As urban areas expand, automatic… 22 Hugging Face Daily Papers research 9d ago Capable but Careless: Do Computer-Use Agents Follow Contextual Integrity? Abstract Computer-use agents frequently expose inappropriate information across applications, prompting the creation of AgentCIBench to evaluate and mitigate privacy risks in cross-application contexts. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Computer-use agents (CUAs) now… 7 Hacker News — AI on Front Page community 9d ago Mistral OCR 4 Article URL: https://mistral.ai/news/ocr-4/ Comments URL: https://news.ycombinator.com/item?id=48645152 Points: 281 # Comments: 71 35 Hugging Face Daily Papers research 9d ago Toward Open Weight Models Without Risks: Separating Public and Private Capabilities in LLMs Abstract Tiered Language Models (TLMs) provide a framework for releasing large language models with configurable capability levels through secret keys that modify computation graphs while maintaining public model integrity. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 21 Hugging Face Daily Papers research 9d ago Arbor: Explicit Geometric Conditioning for Controllable 3D Asset Generation Abstract Arbor enables explicit 3D spatial control in text-conditioned latent generation through constraint meshes that define occupancy, avoidance, and contact regions, maintaining object quality while improving constraint adherence. Generated by Qwen/Qwen2.5-Coder-32B-Instruct… 26 Hugging Face Daily Papers research 9d ago Grouped Query Experts: Mixture-of-Experts on GQA Self-Attention Abstract Grouped Query Experts (GQE) improves Transformer efficiency by selectively activating query heads based on token content while maintaining key-value cache benefits of grouped-query attention. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Self-attention is central to… 25 Hugging Face Daily Papers research 9d ago Training Open Models for Agentic Phone Use Abstract PhoneBuddy combines real and mock app environments to improve training of open models for phone use, demonstrating enhanced task success rates through mixed reinforcement learning approaches. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Phones are becoming an important… 11 llama.cpp releases dev-tools 9d ago b9768 model: Granite Speech Plus ( #24818 ) feat: Add conversion support for Granite Speech Plus Branch: GraniteSpeechPlus AI-usage: full (Bob, OpenCode + Qwen3.6-35b) Signed-off-by: Gabe Goodhart ghart@us.ibm.com feat: Extend granite_speech to support plus multi-layer concatenation… 27 Hugging Face Daily Papers research 9d ago Counsel: A Meta-Evaluation Dataset for Agentic Tasks Abstract A large-scale dataset of human-metaevaluations of LLM critiques for agentic tasks is introduced to improve the calibration and reliability of automated evaluation methods. Generated by Qwen/Qwen2.5-Coder-32B-Instruct As agentic systems tackle increasingly complex… 22 r/LocalLLaMA community 9d ago My local server idling 99% of the time! Guys what you running to make agents busy? Like some crazy 24/7 tasks, or maybe some useful ideas on how to utilize local llm with some purpose/use? I personally running Qwen3.6-27B with owu and with pi for coding (little-coder) but as in title - it’s idling all the time…  … 33 Hugging Face Daily Papers research 9d ago Notes2Skills: From Lab Notebooks to Certainty-Aware Scientific Agent Skills Abstract Notes2Skills framework converts laboratory notes into verifiable skills for AI agents while maintaining author uncertainty levels, addressing gaps in scientific AI development. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Scientific discovery workflows usually contain… 27 Hugging Face Daily Papers research 9d ago BioMatrix: Towards a Comprehensive Biological Foundation Model Spanning the Modality Matrix of Sequences, Structures, and Language Abstract BioMatrix is a novel multimodal foundation model that integrates molecular sequences, structures, and natural language into a unified decoder-only architecture for diverse biological tasks. Generated by Qwen/Qwen2.5-Coder-32B-Instruct We present BioMatrix, the first… 37 Hugging Face Daily Papers research 9d ago SkillHarness: Harnessing Safe Skills for Computer-Use Agents Abstract SkillHarness is a framework that enables computer-use agents to safely learn and execute skills in dynamic environments by incorporating safety constraints and adaptive skill selection mechanisms. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Computer-Use Agents (CUAs)… 24 Hugging Face Daily Papers research 9d ago Improving Text-to-Music Generation with Human Preference Rewards Abstract A text-to-music generation system uses reward conditioning, expert iteration, and preference tuning to improve audio quality while maintaining efficiency within a 120M-parameter model framework. Generated by Qwen/Qwen2.5-Coder-32B-Instruct We describe our entry to the… 19 r/LocalLLaMA community 9d ago Multi Tier MoE Caching I've never seen much discussion around this, but it feels like where MoE inference is heading. The bulk of big models we use, GLM 5.2, Deepseek V4, Stepfun, Minimix are MoE meaning inference is run on a small subsection of the experts. Currently we scatter these experts over a… 9 Hugging Face Daily Papers research 9d ago Unlimited OCR Works Abstract Unlimited OCR introduces Reference Sliding Window Attention to eliminate growing memory consumption during long-sequence OCR tasks, enabling efficient transcription of multiple pages in a single forward pass. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Recently,… 12 Hugging Face Daily Papers research 9d ago Foresight: Failure Detection for Long-Horizon Robotic Manipulation with Action-Conditioned World Model Latents Abstract A failure detection framework for long-horizon robotic tasks uses action-conditioned world models and functional conformal prediction to monitor manipulation trajectories with only final task labels. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Long-horizon tasks are… 8 Hugging Face Daily Papers research 9d ago MeshFlow: Mesh Generation with Equivariant Flow Matching Abstract MeshFlow generates triangle meshes directly using equivariant optimal-transport flow matching models with improved inference speed over autoregressive methods. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Meshes are among the most common 3D scene representations, but… 16 Hugging Face Daily Papers research 9d ago HAKARI-Bench: A Lightweight Benchmark for Comparing Retrieval Architectures and Efficiency Settings under Unified Conditions Abstract HAKARI-Bench provides a lightweight benchmark for comparing retrieval methods across multiple configurations and languages, enabling efficient model selection and performance analysis. Generated by Qwen/Qwen2.5-Coder-32B-Instruct With the rapid spread of… 23 Hugging Face Daily Papers research 9d ago AOHP: An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction Abstract AOHP presents an Android-based operating system framework that treats AI agents as first-class entities, enhancing task completion rates and reducing execution costs through specialized agent-oriented mechanisms. Generated by Qwen/Qwen2.5-Coder-32B-Instruct AI agents… 16 r/LocalLLaMA community 9d ago Training a Qwen 3.5 4B/9B agent for multi-tool use: SFT first or go directly to RL? To train Qwen 3.5 4B or 9B for a custom multi-tool agent workflow and would appreciate guidance from people who have done this successfully. A few questions: SFT → RL or RL-only? - Is it still recommended to first do supervised fine-tuning (tool-calling traces, reasoning… 15 Hugging Face Daily Papers research 9d ago DataClaw0: Agentic Tailoring Multimodal Data from Raw Streams Abstract Agentic Data Tailoring paradigm uses learnable data processing to structure high-entropy multimodal streams, with DataClaw_0-9B model achieving robust alignment through SFT and GRPO on a novel benchmark. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Massive unstructured… 19 Smol AI News news-outlet 9d ago not much happened today **Prime Intellect's `prime-rl` v0.6.0** advances agentic reinforcement learning infrastructure supporting **1 trillion parameter MoE models** with sub-5-minute step times and a **131k context GLM-5 agentic setup**. The release includes optimizations in inference, training, and… 37 r/LocalLLaMA community 9d ago Is there any reason for a lack of love for Gemma 4 26b? The answer to most questions on here is Qwen3.6 27b or 35b and then Gemma4 31b (but lesser so as it doesn’t fit well on a solo 3090). Is there any reason why Gemma 4 26b moe isn’t mentioned more? I plan on using Qwen for my coding agents. But I’ve been building a Jarvis for… 20 Page 8 of 10 · 500 articles ← Newer Older →