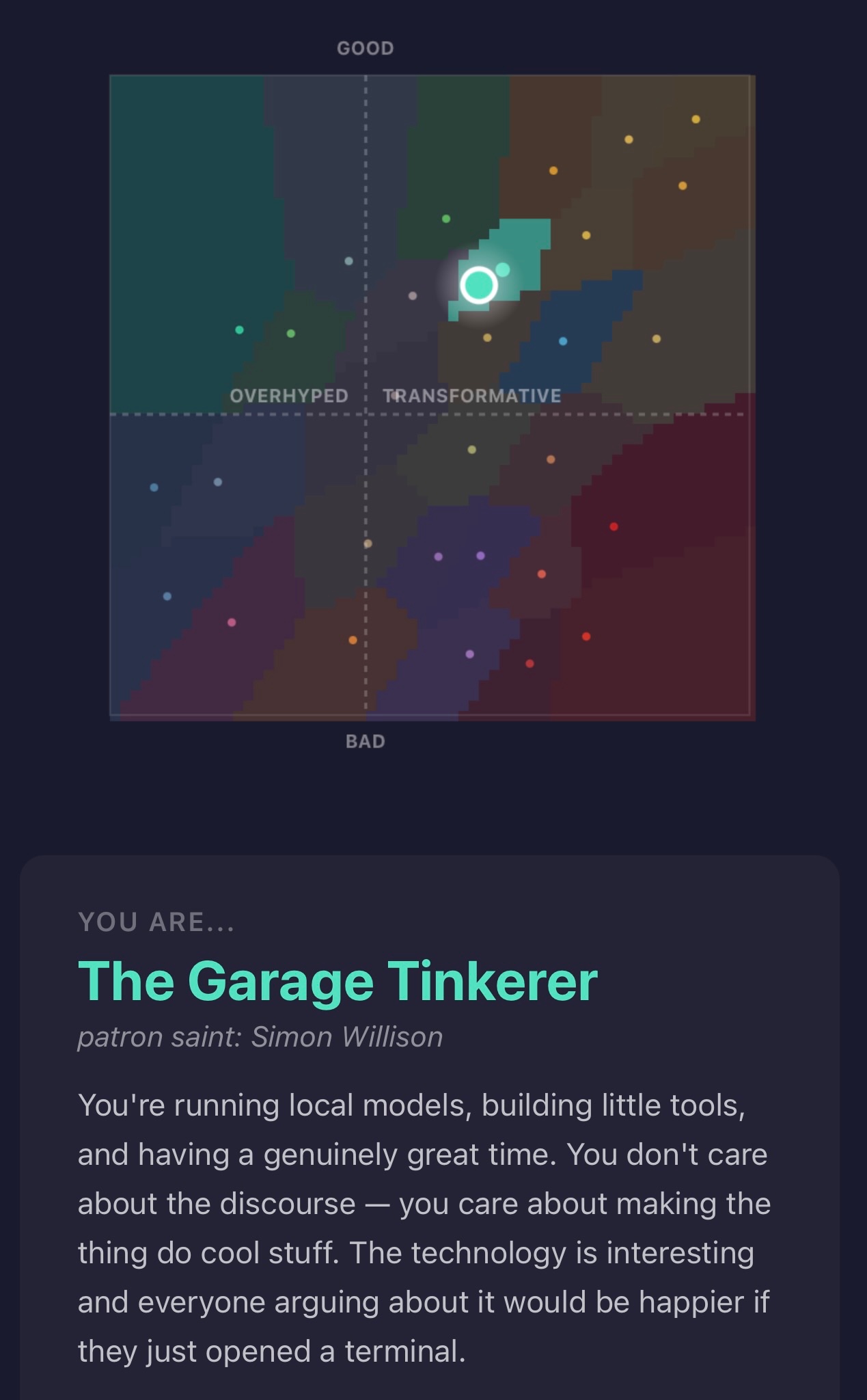
News / #rag Tag Rag 500 articles archived under #rag · RSS Sign in to follow arXiv — Machine Learning research 2h ago TallyTrain: Communication-Efficient Federated Distillation arXiv:2607.00173v1 Announce Type: new Abstract: Federated learning is bandwidth-bound on two orthogonal axes: model size, which limits how often parameter-averaging methods can afford to merge, and class count, which makes per-probe soft-label distillation prohibitive at large… 31 arXiv — Machine Learning research 2h ago K-Inverse-RFM: A Modified RFM that Bridges the Gap to Neural Networks for Data-Corrupted Mathematical Tasks arXiv:2607.00329v1 Announce Type: new Abstract: Recursive Feature Machines (RFMs) are a class of kernel machines that utilize the Average Gradient Outer Product (AGOP) as a mechanism for feature learning. They have been shown to effectively replicate the learning dynamics and… 7 arXiv — Machine Learning research 2h ago Ghost in the Kernel: In-Context Learning with Efficient Transformers via Domain Generalization arXiv:2607.00479v1 Announce Type: new Abstract: Transformer-based large models have demonstrated remarkable generalization abilities across different tasks by leveraging a context-aware attention module for in-context learning. With richer context, transformers adapt more… 18 arXiv — Machine Learning research 2h ago Leveraging Multimodality for Real-Time Classification of Transients and Variables found by the Zwicky Transient Facility arXiv:2607.00228v1 Announce Type: cross Abstract: Modern time-domain surveys such as the Zwicky Transient Facility (ZTF) generate hundreds of thousands of alerts each night, making real-time decisions for follow-up observations a central challenge in time-domain astronomy.… 28 arXiv — NLP / Computation & Language research 2h ago ALEE: Any-Language Evaluation of Embeddings via English-Centric Minimal Pairs arXiv:2607.00171v1 Announce Type: new Abstract: Text embeddings are standard for semantic similarity tasks, yet their evaluation remains an open challenge. Current benchmarks are static, cover only a limited set of languages, are often domain-specific, susceptible to… 4 arXiv — NLP / Computation & Language research 2h ago LV-ROVER: Multi-Stream Tesseract Voting for Maltese Paragraph OCR arXiv:2607.00250v1 Announce Type: new Abstract: Maltese has decent text corpora and pretrained language models, but, like many languages outside the handful with large OCR benchmarks, only a single known real labelled PDF corpus for OCR training, 57 page, far below what… 25 arXiv — NLP / Computation & Language research 2h ago DiscoLoop: Looping Discrete Embeddings and Continuous Hidden States for Multi-hop Reasoning arXiv:2607.00341v1 Announce Type: new Abstract: Large language models achieve strong performance on many reasoning tasks when allowed to externalize intermediate steps as Chain-of-Thought (CoT). However, many questions require the model to internalize the multi-step reasoning… 32 arXiv — NLP / Computation & Language research 2h ago Dual-Confidence Contrastive Decoding for Retrieval-Augmented Generation arXiv:2607.00570v1 Announce Type: new Abstract: Retrieval-augmented generation (RAG) increasingly requires models to answer questions from multiple retrieved documents, where only some sources are relevant and the retrieved bundle may contain stale, noisy, or conflicting… 35 arXiv — NLP / Computation & Language research 2h ago What Survives Into Context: A Diagnostic for Budget-Constrained Multi-Hop RAG and When Submodular Evidence Packing Improves It arXiv:2607.00725v1 Announce Type: new Abstract: Retrieval-augmented generation (RAG) under a fixed reader-context budget forces a selection problem: of the evidence retrieved, only a fraction can be shown to the reader. We argue that document recall -- the standard retrieval… 27 arXiv — NLP / Computation & Language research 2h ago CAT: Confidence-Adaptive Thinking for Efficient Reasoning of Large Reasoning Models arXiv:2607.00862v1 Announce Type: new Abstract: Large Reasoning Models (LRMs) have achieved remarkable success on complex tasks by leveraging long chain-of-thought (CoT) trajectories, yet they frequently exhibit overthinking on simple queries, resulting in significant token… 8 arXiv — NLP / Computation & Language research 2h ago Beyond Document Grounding: Span-Level Hallucination Detection over Code, Tool Output, and Documents arXiv:2607.00895v1 Announce Type: new Abstract: Hallucination detection for retrieval-augmented generation (RAG) is usually evaluated on natural-language document evidence. However, grounded generation systems increasingly rely on structured inputs: source code, developer-tool… 14 arXiv — NLP / Computation & Language research 2h ago Towards Developing a Multimodal Chat Assistant for University Stakeholders: RAG-based Approach arXiv:2607.01115v1 Announce Type: new Abstract: University stakeholders often face difficulties in accessing timely and reliable information, especially in developing countries, where there are very few intelligent support systems. Existing rule-based chatbots are unable to… 15 arXiv — NLP / Computation & Language research 2h ago Adversarial Pragmatics for AI Safety Evaluation: A Benchmark for Instruction Conflict, Embedded Commands, and Policy Ambiguity arXiv:2607.01153v1 Announce Type: new Abstract: Safety evaluations for language models increasingly depend on judgments about ambiguous natural-language behaviour: whether a model has followed an instruction, refused appropriately, complied with a policy, resisted an embedded… 14 arXiv — NLP / Computation & Language research 2h ago Theoria: Rewrite-Acceptability Verification over Informal Reasoning States arXiv:2607.01223v1 Announce Type: cross Abstract: When should an AI system's answer be trusted? Formal proof assistants offer certainty but cannot reach most of the problem distribution; scalar LLM judges offer coverage but produce opaque scores that cannot be audited after the… 18 Hugging Face Daily Papers research 12h ago PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation Abstract PolyFlow introduces a continuous mesh representation using a topology embedder and applies flow-matching with Transformers for parallel mesh generation, achieving faster inference and precise resolution control compared to autoregressive methods. Generated by… 5 Hugging Face Daily Papers research 14h ago Lexical Consensus: Grounded Word Learning and Shared Meaning in Artificial Agents Abstract Grounded word learning experiments using visual embeddings and lexical learners reveal that perceptual distance, rather than semantic relatedness, determines acquisition success, with distinct patterns in naming and retrieval performance. Generated by… 34 r/MachineLearning community 14h ago P Moth-Retrieval: Graph-Free Multi-Hop Retrieval via Query-Time Orchestration (Beating Graph-Based Systems on HotpotQA) [P] We just open-sourced MOTHRAG, a multi-hop RAG framework that skips the knowledge graph entirely. We kept hitting the same wall building multi-hop RAG: the systems with the best accuracy (GraphRAG, HippoRAG, RAPTOR) all lean on a knowledge graph built offline, and that’s great… 27 r/MachineLearning community 15h ago [D] Simple Questions Thread Please post your questions here instead of creating a new thread. Encourage others who create new posts for questions to post here instead! Thread will stay alive until next one so keep posting after the date in the title. Thanks to everyone for answering questions in the… 36 Hugging Face Daily Papers research 20h ago DataEvolver: Self-Evolving Multi-Agent Data Construction for Text-Rich Image Generation Abstract DataEvolver is a self-evolving multi-agent framework that improves text-rich image generation by leveraging feedback from rejected samples to iteratively enhance data quality. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Text-rich image generation is one of the most… 11 Hugging Face Daily Papers research 23h ago Little Brains, Big Feats: Exploring Compact Language Models Abstract Small language models can effectively perform retrieval-augmented generation tasks directly on-device without GPU acceleration. Generated by Qwen/Qwen2.5-Coder-32B-Instruct While large language models have been dominating the research landscape recently, small language… 13 arXiv — Machine Learning research 1d ago Quality-Aware Modulation for Diffusion Transformers arXiv:2606.30934v1 Announce Type: new Abstract: Modern text-to-image diffusion models, such as diffusion transformers (DiT), rely on timestep or prompt embeddings to modulate the strength of the denoising process in each timestep. While this modulation communicates the current… 31 arXiv — Machine Learning research 1d ago Visualizing High-Dimensional Graph Embeddings via Informed Multi-View Projections arXiv:2606.31119v1 Announce Type: new Abstract: Graphs are commonly visualized in 2D, where humans readily interpret spatial relationships, yet such layouts often distort higher-dimensional structure. We propose to embed graphs in high-dimensional space and search for… 38 arXiv — Machine Learning research 1d ago Transformers as Bayesian In-Context Experimenters: Smoothness-Adaptive Efficient ATE Estimation arXiv:2606.31184v1 Announce Type: new Abstract: Adaptive experiments for average treatment effects (ATE) require randomized allocations balancing valid inference with statistical efficiency. The oracle design is a covariate-dependent Neyman rule governed by unknown… 18 arXiv — Machine Learning research 1d ago Probing Memorization of Tabular In-Context Learning arXiv:2606.31208v1 Announce Type: new Abstract: Large tabular models (LTMs), i.e., tabular foundation models leveraging in-context learning (ICL), achieve state-of-the-art performance on tabular tasks. While LLMs are known to unintentionally memorize training data, the… 19 arXiv — Machine Learning research 1d ago FedXDS: Leveraging Model Attribution Methods to counteract Data Heterogeneity in Federated Learning arXiv:2606.31742v1 Announce Type: new Abstract: Explainable AI (XAI) methods have demonstrated significant success in recent years at identifying relevant features in input data that drive deep learning model decisions, enhancing interpretability for users. However, the… 4 arXiv — NLP / Computation & Language research 1d ago SemRF: A Semantic Reference Frame for Residual-Stream Dynamics in Language Models arXiv:2606.32022v1 Announce Type: cross Abstract: Residual-stream analysis asks how language-model computation evolves across depth, but intermediate decoding requires comparable readout coordinates across layers. If embedding anchors and unembedding readout disagree on the… 23 arXiv — Machine Learning research 1d ago Listening Between the Lines: Joint Learning of ASR Embeddings and LLM-Augmented Linguistics for Dementia Detection arXiv:2606.30675v1 Announce Type: cross Abstract: Early detection of dementia through speech analysis offers a non-invasive screening alternative, but capturing both acoustic and linguistic biomarkers remains challenging. We propose a multimodal framework leveraging Whisper for… 28 arXiv — NLP / Computation & Language research 1d ago CORTEX: Token-Level Hallucination Detection in RAG via Comparative Internal Representations arXiv:2606.31033v1 Announce Type: new Abstract: In this paper, we propose CORTEX, a token-level hallucination detection method for Retrieval-Augmented Generation (RAG). In long-form RAG outputs, hallucinations often arise in localized spans rather than throughout an entire… 20 arXiv — NLP / Computation & Language research 1d ago Robust Text Watermarking for Large Language Models via Dual Semantic Embeddings arXiv:2606.31602v1 Announce Type: new Abstract: This work presents Dual-Embedding Watermarking (DEW), a semantic watermarking scheme for large language models (LLMs) that leverages contextual and token-level embeddings to enhance robustness against paraphrasing and translation.… 8 arXiv — NLP / Computation & Language research 1d ago STEB: Style Text Embedding Benchmark arXiv:2606.31741v1 Announce Type: new Abstract: While semantic embeddings are rigorously evaluated on the Massive Text Embedding Benchmark, the evaluation of style embeddings remains fragmented, with each work relying on their own set of tasks and datasets. To bridge this gap,… 27 arXiv — NLP / Computation & Language research 1d ago Information Terra: A Narrative-Anchored Semantic-First Projection of Document Embeddings arXiv:2606.30824v1 Announce Type: cross Abstract: We introduce Information Terra, a narrative-anchored semantic-first projection that places a document corpus on an Earth-like globe whose poles are two user-chosen endpoint documents and whose prime meridian is the great-circle… 28 arXiv — NLP / Computation & Language research 1d ago Learning from Failure: Inference-Time Self-Improvement for Computer-Use Agents arXiv:2606.31270v1 Announce Type: cross Abstract: Computer-use agents, which leverage multimodal large language models (MLLMs) to operate computers and complete tasks, have attracted significant attention for their utility and versatility. A major challenge in developing these… 20 TechCrunch — AI news-outlet 1d ago The DeepMind trio who built a poker AI are now making money for quant hedge funds EquiLibre Technologies, a Prague-based AI lab founded by three ex-DeepMind researchers, is now valued at more than $500 million. 24 Hugging Face Daily Papers research 1d ago LLM Program Optimization via Retrieval Augmented Search Abstract Blackbox adaptation methods using retrieval-augmented search and atomic edit decomposition improve program optimization performance for both C++ and Python code. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Recent work has demonstrated the potential of large language… 19 Simon Willison community 1d ago The AI Compass The AI Compass This political compass style quiz by bambamramfan is pretty neat - answer 29 questions about AI and AI ethics to see which of the 30 archetypes you best fit. I'm impressed that my answers on my first time through the quiz categorized me as "The Garage Tinkerer",… 23 r/LocalLLaMA community 1d ago HIP: use hipBLAS for dense prefill on gfx900, keep MMQ for MoE by DEV-DUFORD · Pull Request #24588 · ggml-org/llama.cpp Overall Performance Gains: Qwen3.5 4B : +36.1% Qwen3.6 27B : +18.9% Gemma4 12B : +65.1% Overall average : ~40% Only for gfx900 related GPUs: Vega GPU, codename vega10, including Radeon Vega Frontier Edition, Radeon RX Vega 56/64, Radeon RX Vega 64 Liquid, Radeon Pro Vega… 5 r/LocalLLaMA community 1d ago Benchmarked Graph-RAG vs. Graph-Free Multi-Hop RAG: The graph mostly bought us a massive rebuild bill, not accuracy. We kept hitting the same wall building multi-hop RAG: the systems with the best accuracy (GraphRAG, HippoRAG 2, RAPTOR) all lean on a knowledge graph built offline - and that’s great numbers, until the moment your data changes! Every update means re-running an LLM indexing pass… 11 Hugging Face Daily Papers research 1d ago SAM2Matting: Generalized Image and Video Matting Abstract SAM2Matting advances video matting by decoupling tracking and matting tasks through a tracker-to-matting framework that leverages foundational trackers with region-proposal bridges and dedicated matting heads. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Despite… 36 Hugging Face Daily Papers research 1d ago TheoremGraph: Bridging Formal and Informal Mathematics Abstract A unified mathematical dependency graph connects informal and formal mathematics through semantic embedding and automated extraction from arXiv papers and Lean projects. Generated by Qwen/Qwen2.5-Coder-32B-Instruct Mathematical knowledge is organized around statements… 32 arXiv — Machine Learning research 2d ago Geometric Measurements of the Axiom of Choice in Neural Proof Embeddings arXiv:2606.28572v1 Announce Type: new Abstract: The axiom of choice has divided the foundations of mathematics for over a century, but the distinction between classical and constructive proofs has remained a philosophical and methodological one. We use Lean 4's kernel-level… 8 arXiv — Machine Learning research 2d ago How Token Influence Decays with Distance: A Green-Function View of Trained Language Models arXiv:2606.29139v1 Announce Type: new Abstract: We study how the next-token prediction of an autoregressive Transformer language model changes under small perturbations of earlier input token embeddings. Motivated by operator learning and iterative solvers for differential… 27 arXiv — Machine Learning research 2d ago Deterministic Decisions for High-Stakes AI. A Zero-Egress Pipeline with the Deployability of RAG and the Accuracy of Machine Learning arXiv:2606.29280v1 Announce Type: new Abstract: We identify intervention bias as a previously unquantified failure mode of zero-shot large-language-model (LLM) educational advisory agents: without task-specific training, they recommend action when a hindsight-optimal oracle… 31 arXiv — Machine Learning research 2d ago SP-CACW: Convergence-Aware Client Weighting for Selfish Personalized Learning arXiv:2606.29322v1 Announce Type: new Abstract: Collaborative learning is sustainable only when it benefits each participant. Standard federated learning optimizes a global average objective, which can under perform for clients whose data distributions differ substantially from… 35 arXiv — Machine Learning research 2d ago Deciphering Region-Level Signatures from Latency Measurements in LEO Satellite Internet arXiv:2606.29324v1 Announce Type: new Abstract: Low-Earth orbit (LEO) satellite Internet has become an indispensable infrastructure that provide growing coverage for global users. Despite extensive measurement efforts, the principles underlying region-level performance… 32 arXiv — Machine Learning research 2d ago The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning arXiv:2606.29526v1 Announce Type: new Abstract: Reinforcement learning (RL) has gained growing attention in large language model (LLM) post-training, yet RL training remains fragile and can suffer from instability or collapse. One vital cause is training-inference mismatch: LLM… 17 arXiv — NLP / Computation & Language research 2d ago Turn-Averaged SAEs for Feature Discovery and Long-Context Attribution arXiv:2606.28548v1 Announce Type: new Abstract: Sparse autoencoders (SAEs) have become a useful tool for extracting interpretable features in language models. However, standard SAE architectures operate on individual token activations, meaning that the number of active features… 25 arXiv — NLP / Computation & Language research 2d ago AnTenA: Actionable and Explainable Tensor Analysis System with Large Language Models arXiv:2606.28708v1 Announce Type: new Abstract: Accurately explaining hidden patterns in multi-aspect data has typically been done by leveraging labels and/or accompanying auxiliary metadata. However, labels and auxiliary data may be inaccurate (e.g. nonstandard, inconsistent),… 21 arXiv — NLP / Computation & Language research 2d ago 5ting at SemEval-2026 Task 8: Strong End-to-End Multi-Turn RAG via LLM-Based Reranking and Faithfulness Control arXiv:2606.28737v1 Announce Type: new Abstract: We introduce 5ting, our system for the SemEval2026 Task 8 (MTRAGEval), which evaluates multi-turn Retrieval Augmented Generation (RAG) systems. Multi turn RAG involves context drift, under specification, and hallucination risk. Our… 5 arXiv — NLP / Computation & Language research 2d ago BERTomelo: Your Portuguese Encoder Best Friend arXiv:2606.28999v1 Announce Type: new Abstract: Encoders have become the state of the art for multiple NLP tasks, especially those requiring deep contextual understanding. While multilingual models offer broad coverage, dedicated monolingual encoders are essential for capturing… 16 arXiv — NLP / Computation & Language research 2d ago How to Leverage Synthetic Speech for LLM-Based ASR Systems? arXiv:2606.29031v1 Announce Type: new Abstract: In regulated domains such as banking and healthcare, where privacy constraints make real speech costly to collect and retain, synthetic speech from modern text-to-speech (TTS) is an appealing alternative for training automatic… 15 Page 1 of 10 · 500 articles Older →